本文共 43858 字,大约阅读时间需要 146 分钟。
Linux简介及Ubuntu安装
Linux,免费开源,多用户多任务系统。基于Linux有多个版本的衍生。RedHat、Ubuntu、Debian
安装VMware或VirtualBox虚拟机。具体安装步骤,找百度。
再安装Ubuntu。具体安装步骤,找百度。
Linux常用指令
ls 显示文件或目录
-l 列出文件详细信息l(list)
-a 列出当前目录下所有文件及目录,包括隐藏的a(all)
mkdir 创建目录
-p 创建目录,若无父目录,则创建p(parent)
cd 切换目录
touch 创建空文件
echo 创建带有内容的文件。
cat 查看文件内容
cp 拷贝
mv 移动或重命名
rm 删除文件
-r 递归删除,可删除子目录及文件
-f 强制删除
find 在文件系统中搜索某文件
wc 统计文本中行数、字数、字符数
grep 在文本文件中查找某个字符串
rmdir 删除空目录
tree 树形结构显示目录,需要安装tree包
pwd 显示当前目录
ln 创建链接文件
more、less 分页显示文本文件内容
head、tail 显示文件头、尾内容
ctrl+alt+F1 命令行全屏模式
1. 在终端下:
复制命令:Ctrl + Shift + C 组合键.
粘贴命令:Ctrl + Shift + V 组合键.
2. 在控制台下:
复制命令:Ctrl + Insert 组合键 或 用鼠标选中即是复制。
粘贴命令:Shift + Insert 组合键 或 单击鼠标滚轮即为粘贴。
Export是查看环境变量的
env显示所有的环境变量
set命令显示所有本地定义的Shell变量
echo命令查看单个环境变量
Linux环境变量的设置和查看方法
1. 显示环境变量HOME
$ echo $HOME
/home/redbooks
2. 设置一个新的环境变量hello
$ export HELLO="Hello!"
$ echo $HELLO
Hello!
1.Linux的变量种类
按变量的生存周期来划分,Linux变量可分为两类:
1.1 永久的:需要修改配置文件,变量永久生效。
1.2 临时的:使用export命令声明即可,变量在关闭shell时失效。
2.设置变量的三种方法
2.1 在/etc/profile文件中添加变量【对所有用户生效(永久的)】
用VI在文件/etc/profile文件中增加变量,该变量将会对Linux下所有用户有效,并且是“永久的”。
例如:编辑/etc/profile文件,添加CLASSPATH变量
# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行# source /etc/profile不然只能在下次重进此用户时生效。
2.2 在用户目录下的.bash_profile文件中增加变量【对单一用户生效(永久的)】
用VI在用户目录下的.bash_profile文件中增加变量,改变量仅会对当前用户有效,并且是“永久的”。
例如:编辑guok用户目录(/home/guok)下的.bash_profile
$ vi /home/guok/.bash.profile
添加如下内容:
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行$ source /home/guok/.bash_profile不然只能在下次重进此用户时生效。
2.3 直接运行export命令定义变量【只对当前shell(BASH)有效(临时的)】
在shell的命令行下直接使用[export 变量名=变量值] 定义变量,该变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新shell时就没有这个变量,需要使用的话还需要重新定义。
系统管理命令
stat 显示指定文件的详细信息,比ls更详细
who 显示在线登陆用户
whoami 显示当前操作用户
hostname 显示主机名
uname 显示系统信息
top 动态显示当前耗费资源最多进程信息
ps 显示瞬间进程状态 ps -aux
du 查看目录大小 du -h /home带有单位显示目录信息
df 查看磁盘大小 df -h 带有单位显示磁盘信息
ifconfig 查看网络情况
ping 测试网络连通
netstat 显示网络状态信息
man 命令不会用了,找男人 如:man ls
clear 清屏
alias 对命令重命名 如:alias showmeit="ps -aux" ,另外解除使用unaliax showmeit
kill 杀死进程,可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程。
打包压缩相关命令
gzip:
bzip2:
tar: 打包压缩
-c 归档文件
-x 压缩文件
-z gzip压缩文件
-j bzip2压缩文件
-v 显示压缩或解压缩过程 v(view)
-f 使用档名
例:
tar -cvf /home/abc.tar /home/abc 只打包,不压缩
tar -zcvf /home/abc.tar.gz /home/abc 打包,并用gzip压缩
tar -jcvf /home/abc.tar.bz2 /home/abc 打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令 tar -cvf / tar -zcvf / tar -jcvf 中的“c” 换成“x” 就可以了。
tar命令可以用来压缩打包单文件、多个文件、单个目录、多个目录。
常用格式:
单个文件压缩打包 tar czvf my.tar.gz file1
多个文件压缩打包 tar czvf my.tar.gz file1 file2,...(file*)(也可以给file*文件mv 目录在压缩)
单个目录压缩打包 tar czvf my.tar.gz dir1
多个目录压缩打包 tar czvf my.tar.gz dir1 dir2
解包至当前目录:tar xzvf my.tar.gz
1、把/home目录下面的mydata目录压缩为mydata.zip
zip -r mydata.zip mydata #压缩mydata目录 2、把/home目录下面的mydata.zip解压到mydatabak目录里面 unzip mydata.zip -d mydatabak 3、把/home目录下面的abc文件夹和123.txt压缩成为abc123.zip zip -r abc123.zip abc 123.txt 4、把/home目录下面的wwwroot.zip直接解压到/home目录里面 unzip wwwroot.zip 5、把/home目录下面的abc12.zip、abc23.zip、abc34.zip同时解压到/home目录里面 unzip abc*.zip 6、查看把/home目录下面的wwwroot.zip里面的内容 unzip -v wwwroot.zip 7、验证/home目录下面的wwwroot.zip是否完整 unzip -t wwwroot.zip 8、把/home目录下面wwwroot.zip里面的所有文件解压到第一级目录 unzip -j wwwroot.zip主要参数
-c:将解压缩的结果
-l:显示压缩文件内所包含的文件 -p:与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任何的转换 -t:检查压缩文件是否正确 -u:与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中的其它文件解压缩到目录中 -v:执行是时显示详细的信息 -z:仅显示压缩文件的备注文字 -a:对文本文件进行必要的字符转换 -b:不要对文本文件进行字符转换 -C:压缩文件中的文件名称区分大小写 -j:不处理压缩文件中原有的目录路径 -L:将压缩文件中的全部文件名改为小写 -M:将输出结果送到more程序处理 -n:解压缩时不要覆盖原有的文件 -o:不必先询问用户,unzip执行后覆盖原有文件 -P:使用zip的密码选项 -q:执行时不显示任何信息 -s:将文件名中的空白字符转换为底线字符 -V:保留VMS的文件版本信息 -X:解压缩时同时回存文件原来的UID/GID下面是我遇到的:
1,zip文件解压到制定目录
unzip -n nerdtree.zip -d nerdtree
2,查看zip文件里面的内容
unzip -v nerdtree.zip
【软链接】
一种连接称之为符号连接(Symbolic Link),也叫软连接。软链接文件有类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。
用法:ln -s 源文件 目标文件。
当 我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在其它的 目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。例如:ln -s /bin/less /usr/local/bin/less-s 是代号(symbolic)的意思。这 里有两点要注意:第一,ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;第二,ln的链接又软链接 和硬链接两种,软链接就是ln -s ** **,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接ln ** **,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。不论是硬连结或软链结都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。 -f : 链结时先将与 dist 同档名的档案删除 -d : 允许系统管理者硬链结自己的目录 -i : 在删除与 dist 同档名的档案时先进行询问 -n : 在进行软连结时,将 dist 视为一般的档案 -s : 进行软链结(symbolic link) -v : 在连结之前显示其档名 -b : 将在链结时会被覆写或删除的档案进行备份 -S SUFFIX : 将备份的档案都加上 SUFFIX 的字尾 -V METHOD : 指定备份的方式 --help : 显示辅助说明 --version : 显示版本
【硬连接】
硬连接指通过索引节点来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
通过实验加深理解
[oracle@Linux]$ vi test.log #创建一个测试文件f1 [oracle@Linux]$ ln test.log test1.log #创建f1的一个硬连接文件test1.log [oracle@Linux]$ ln -s test.log test2.log #创建f1的一个符号连接文件test2.log [oracle@Linux]$ ls -li # -i参数显示文件的inode节点信息两种链接的区别:
硬链接文件有两个限制
1)、不允许给目录创建硬链接; 2)、只有在同一文件系统中的文件之间才能创建链接,而且只有超级用户才有建立硬链接权限。 对硬链接文件进行读写和删除操作时候,结果和软链接相同。但如果我们删除硬链接文件的源文件,硬链接文件仍然存在,而且保留了愿有的内容。这时,系统就“忘记”了它曾经是硬链接文件。而把他当成一个普通文件。
那么我们就可以这样理解:硬连接指通过索引节点来进行的连接,其作用是允许一个文件拥有多个有效路径名,能够达到误删除的作用。
其原因是因为对应的文件的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它
的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。文件才会被真正删除。
注:保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index即I节点)。
软链接没有硬链接以上的两个限制,因而现在更为广泛使用,它具有更大的灵活性,甚至可以跨越不同机器、不同网络对文件进行链接。但是软链接的缺点在于:因为链接文件包含有原文件的路径信息,所以当原文件从一个目录下移到其他目录中,再访问链接文件,系统就找不到了,而硬链接就没有这个缺陷,你想怎么移就怎么移;还有它要系统分配额外的空间用于建立新的索引节点和保存原文件的路径。
linux find 忽略permission denied”
1.直接丢弃错误信息
find / -name "#.txt" 2>/dev/null
2.或者将错误输出到指定txt
find / -name "#.txt" 2>/home/error.txt
关机/重启机器
shutdown
-r 关机重启
-h 关机不重启
now 立刻关机
halt 关机
reboot 重启
Linux管道
将一个命令的标准输出作为另一个命令的标准输入。也就是把几个命令组合起来使用,后一个命令除以前一个命令的结果。
例:grep -r "close" /home/* | more 在home目录下所有文件中查找,包括close的文件,并分页输出。
Linux软件包管理
dpkg (Debian Package)管理工具,软件包名以.deb后缀。
这种方法适合系统不能联网的情况下。
比如安装tree命令的安装包,先将tree.deb传到Linux系统中。再使用如下命令安装。
sudo dpkg -i tree_1.5.3-1_i386.deb 安装软件
sudo dpkg -r tree 卸载软件
注:将tree.deb传到Linux系统中,有多种方式。VMwareTool,使用挂载方式;使用winSCP工具等;
APT(Advanced Packaging Tool)高级软件工具。
这种方法适合系统能够连接互联网的情况。
依然以tree为例
sudo apt-get install tree 安装tree
sudo apt-get remove tree 卸载tree
sudo apt-get update 更新软件
sudo apt-get upgrade
将.rpm文件转为.deb文件
.rpm为RedHat使用的软件格式。在Ubuntu下不能直接使用,所以需要转换一下。
sudo alien abc.rpm
sed替换
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作,下面先了解一下sed的用法
sed命令行格式为: sed [-nefri] ‘command’ 输入文本常用选项: -n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e∶直接在指令列模式上进行 sed 的动作编辑; -f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作; -r∶sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法) -i∶直接修改读取的档案内容,而不是由萤幕输出。常用命令:
a ∶新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ c ∶取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! d ∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚; i ∶插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); p ∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~ s ∶取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!举例:(假设我们有一文件名为ab)
删除某行 [root@localhost ruby] # sed '1d' ab #删除第一行 [root@localhost ruby] # sed '$d' ab #删除最后一行 [root@localhost ruby] # sed '1,2d' ab #删除第一行到第二行 [root@localhost ruby] # sed '2,$d' ab #删除第二行到最后一行显示某行
. [root@localhost ruby] # sed -n '1p' ab #显示第一行 [root@localhost ruby] # sed -n '$p' ab #显示最后一行 [root@localhost ruby] # sed -n '1,2p' ab #显示第一行到第二行 [root@localhost ruby] # sed -n '2,$p' ab #显示第二行到最后一行使用模式进行查询
[root@localhost ruby] # sed -n '/ruby/p' ab #查询包括关键字ruby所在所有行 [root@localhost ruby] # sed -n '/\$/p' ab #查询包括关键字$所在所有行,使用反斜线\屏蔽特殊含义增加一行或多行字符串
[root@localhost ruby]# cat ab Hello! ruby is me,welcome to my blog. end [root@localhost ruby] # sed '1a drink tea' ab #第一行后增加字符串"drink tea" Hello! drink tea ruby is me,welcome to my blog. end [root@localhost ruby] # sed '1,3a drink tea' ab #第一行到第三行后增加字符串"drink tea" Hello! drink tea ruby is me,welcome to my blog. drink tea end drink tea [root@localhost ruby] # sed '1a drink tea\nor coffee' ab #第一行后增加多行,使用换行符\n Hello! drink tea or coffee ruby is me,welcome to my blog. end代替一行或多行
[root@localhost ruby] # sed '1c Hi' ab #第一行代替为Hi Hi ruby is me,welcome to my blog. end [root@localhost ruby] # sed '1,2c Hi' ab #第一行到第二行代替为Hi Hi end替换一行中的某部分
格式:sed 's/要替换的字符串/新的字符串/g' (要替换的字符串可以用正则表达式) [root@localhost ruby] # sed -n '/ruby/p' ab | sed 's/ruby/bird/g' #替换ruby为bird [root@localhost ruby] # sed -n '/ruby/p' ab | sed 's/ruby//g' #删除ruby插入
[root@localhost ruby] # sed -i '$a bye' ab #在文件ab中最后一行直接输入"bye" [root@localhost ruby]# cat ab Hello! ruby is me,welcome to my blog. end bye删除匹配行
sed -i '/匹配字符串/d' filename (注:若匹配字符串是变量,则需要“”,而不是‘’。记得好像是)
替换匹配行中的某个字符串
sed -i '/匹配字符串/s/替换源字符串/替换目标字符串/g' filename
sed -i "s!CURRENTPATH!`pwd`!g" filename #将文件filename中的CURRENTPATH替换为当前全路径
curpath=`pwd` #取当前全路径 echo Name=${curpath##*/} >> ./filename #取当前的目录名(不是全路径)赋值给Name,然后输出到文件filenameecho Exec=`pwd` >> ./filename #取当前全路径赋值给Exec,然后输出到文件filename
用户及用户组管理
/etc/passwd 存储用户账号
/etc/group 存储组账号
/etc/shadow 存储用户账号的密码
/etc/gshadow 存储用户组账号的密码
useradd 用户名
userdel 用户名
adduser 用户名
groupadd 组名
groupdel 组名
passwd root 给root设置密码
su root
su - root
/etc/profile 系统环境变量
bash_profile 用户环境变量
.bashrc 用户环境变量
su user 切换用户,加载配置文件.bashrc
su - user 切换用户,加载配置文件/etc/profile ,加载bash_profile
更改文件的用户及用户组
sudo chown [-R] owner[:group] {File|Directory}
例如:还以jdk-7u21-linux-i586.tar.gz为例。属于用户hadoop,组hadoop
要想切换此文件所属的用户及组。可以使用命令。
sudo chown root:root jdk-7u21-linux-i586.tar.gz
文件权限管理
三种基本权限
R 读 数值表示为4
W 写 数值表示为2
X 可执行 数值表示为1
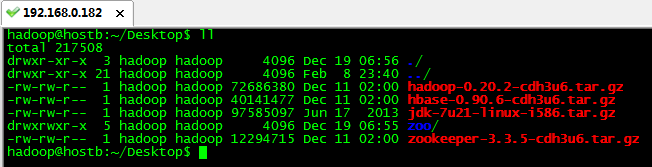
如图所示,jdk-7u21-linux-i586.tar.gz文件的权限为-rw-rw-r--
-rw-rw-r--一共十个字符,分成四段。
第一个字符“-”表示普通文件;这个位置还可能会出现“l”链接;“d”表示目录
第二三四个字符“rw-”表示当前所属用户的权限。 所以用数值表示为4+2=6
第五六七个字符“rw-”表示当前所属组的权限。 所以用数值表示为4+2=6
第八九十个字符“r--”表示其他用户权限。 所以用数值表示为2
所以操作此文件的权限用数值表示为662
更改权限
sudo chmod [u所属用户 g所属组 o其他用户 a所有用户] [+增加权限 -减少权限] [r w x] 目录名
例如:有一个文件filename,权限为“-rw-r----x” ,将权限值改为"-rwxrw-r-x",用数值表示为765
sudo chmod u+x g+w o+r filename
上面的例子可以用数值表示
sudo chmod 765 filename
rwx以及sStT权限
众所周知,一个文件都有一个所有者, 表示该文件是谁创建的. 同时, 该文件还有一个组编号, 表示该文件所属的组, 一般为文件所有者所属的组.
如果是一个可执行文件, 那么在执行时, 一般该文件只拥有调用该文件的用户具有的权限. 而setuid, setgid 可以来改变这种设置.
setuid:该位是让普通用户可以以root用户的角色运行只有root帐号才能运行的程序或命令。比如我们用普通用户运行passwd命令来更改自己的口令,实际上最终更改的是/etc/passwd文件我们知道/etc/passwd文件是用户管理的配置文件,只有root权限的用户才能更改
[root@localhost ~]# ls -l /etc/passwd
-rw-r--r-- 1 root root 2379 04-21 13:18 /etc/passwd
作为普通用户如果修改自己的口令通过修改/etc/passwd肯定是不可完成的任务,但是不是可以通过一个命令来修改呢答案是肯定的,作为普通用户可以通过passwd 来修改自己的口令这归功于passwd命令的权限我们来看一下;
[root@localhost ~]# ls -l /usr/bin/passwd
-r-s--x--x 1 root root 21944 02-12 16:15 /usr/bin/passwd
因为/usr/bin/passwd 文件已经设置了setuid 权限位(也就是r-s--x--x中的s),所以普通用户能临时变成root,间接的修改/etc/passwd,以达到修改自己口令的权限
setgid: 该权限只对目录有效. 目录被设置该位后, 任何用户在此目录下创建的文件都具有和该目录所属的组相同的组.
sticky bit: 该位可以理解为防删除位. 一个文件是否可以被某用户删除, 主要取决于该文件所属的组是否对该用户具有写权限. 如果没有写权限, 则这个目录下的所有文件都不能被删除, 同时也不能添加新的文件. 如果希望用户能够添加文件但同时不能删除文件, 则可以对文件使用sticky bit位. 设置该位后, 就算用户对目录具有写权限, 也不能删除该文件.
下面说一下如何操作这些标志:
操作这些标志与操作文件权限的命令是一样的, 都是 chmod. 有两种方法来操作,
1) chmod u+s temp -- 为temp文件加上setuid标志. (setuid 只对文件有效)
chmod g+s tempdir -- 为tempdir目录加上setgid标志 (setgid 只对目录有效)
chmod o+t temp -- 为temp文件加上sticky标志 (sticky只对文件有效)
2) 采用八进制方式. 对一般文件通过三组八进制数字来置标志, 如 666, 777, 644等. 如果设置这些特殊标志, 则在这组数字之外外加一组八进制数字. 如 4666, 2777等. 这一组八进制数字三位的意义如下,
abc
a - setuid位, 如果该位为1, 则表示设置setuid 4---
b - setgid位, 如果该位为1, 则表示设置setgid 2---
c - sticky位, 如果该位为1, 则表示设置sticky 1---
设置完这些标志后, 可以用 ls -l 来查看. 如果有这些标志, 则会在原来的执行标志位置上显示. 如
rwsrw-r-- 表示有setuid标志
rwxrwsrw- 表示有setgid标志
rwxrw-rwt 表示有sticky标志
那么原来的执行标志x到哪里去了呢? 系统是这样规定的, 如果本来在该位上有x, 则这些特殊标志显示为小写字母 (s, s, t). 否则, 显示为大写字母 (S, S, T)
注意:setuid和setgid会面临风险,所以尽可能的少用。
linux 基本命令
ls (list 显示当前目录下文件和目录 ls -l 详细显示 =ll ) [root@linux ~]# ls [-aAdfFhilRS] 目录名称 [root@linux ~]# ls [--color={none,auto,always}] 目录名称 [root@linux ~]# ls [--full-time] 目录名称 参数: -a :全部的档案,连同隐藏档( 开头为 . 的档案) 一起列出来~ -A :全部的档案,连同隐藏档,但不包括 . 与 .. 这两个目录,一起列出来~ -d :仅列出目录本身,而不是列出目录内的档案数据 -f :直接列出结果,而不进行排序 (ls 预设会以档名排序!) -F :根据档案、目录等信息,给予附加数据结构,例如: *:代表可执行档; /:代表目录; =:代表 socket 档案; |:代表 FIFO 档案; -h :将档案容量以人类较易读的方式(例如 GB, KB 等等)列出来; -i :列出 inode 位置,而非列出档案属性; -l :长数据串行出,包含档案的属性等等数据; -n :列出 UID 与 GID 而非使用者与群组的名称 (UID与GID会在账号管理提到!) -r :将排序结果反向输出,例如:原本档名由小到大,反向则为由大到小; -R :连同子目录内容一起列出来; -S :以档案容量大小排序! -t :依时间排序 --color=never :不要依据档案特性给予颜色显示; --color=always :显示颜色 --color=auto :让系统自行依据设定来判断是否给予颜色 --full-time :以完整时间模式 (包含年、月、日、时、分) 输出 --time={atime,ctime} :输出 access 时间或 改变权限属性时间 (ctime) 而非内容变更时间 (modification time) cat 由第一行开始显示档案内容 [root@linux ~]# cat [-AEnTv] 参数: -A :相当于 -vET 的整合参数,可列出一些特殊字符~ -E :将结尾的断行字符 $ 显示出来; -n :打印出行号; -T :将 [tab] 按键以 ^I 显示出来; -v :列出一些看不出来的特殊字符 tac 从最后一行开始显示,可以看出 tac 是 cat 的倒着写! nl 显示的时候,顺道输出行号! [root@linux ~]# nl [-bnw] 档案 参数: -b :指定行号指定的方式,主要有两种: -b a :表示不论是否为空行,也同样列出行号; -b t :如果有空行,空的那一行不要列出行号; -n :列出行号表示的方法,主要有三种: -n ln :行号在屏幕的最左方显示; -n rn :行号在自己字段的最右方显示,且不加 0 ; -n rz :行号在自己字段的最右方显示,且加 0 ; -w :行号字段的占用的位数。 more 一页一页的显示档案内容 空格键 (space):代表向下翻一页; Enter :代表向下翻『一行』; /字符串 :代表在这个显示的内容当中,向下搜寻『字符串』; :f :立刻显示出文件名以及目前显示的行数; q :代表立刻离开 more ,不再显示该档案内容。 less 与 more 类似,但是比 more 更好的是,他可以往前翻页! 空格键 :向下翻动一页; [pagedown]:向下翻动一页; [pageup] :向上翻动一页; /字符串 :向下搜寻『字符串』的功能; ?字符串 :向上搜寻『字符串』的功能; n :重复前一个搜寻 (与 / 或 ? 有关!) N :反向的重复前一个搜寻 (与 / 或 ? 有关!) q :离开 less 这个程序; head 只看头几行 [root@linux ~]# head [-n number] 档案 参数: -n :后面接数字,代表显示几行的意思 tail 只看尾巴几行 tail -200f logfile2 ( 显示日志最后 200 行 ) od 以二进制的方式读取档案内容! [root@linux ~]# od [-t TYPE] 档案 参数: -t :后面可以接各种『类型 (TYPE)』的输出,例如: a :利用预设的字符来输出; c :使用 ASCII 字符来输出 d[size] :利用十进制(decimal)来输出数据,每个整数占用 size bytes ; f[size] :利用浮点数值(floating)来输出数据,每个数占用 size bytes ; o[size] :利用八进位(octal)来输出数据,每个整数占用 size bytes ; x[size] :利用十六进制(hexadecimal)来输出数据,每个整数占用 size bytes ; chmod ( chmod +R filename增加文件读写执行权限,+R 可读,+W 可写,+X 可执行 ( chmod 777 filename 增加文件读写执行权限的另一种方式, 7=> 对应8进制的 111 可读可写可执行) chown ( chown -R haowen .将当前目录下所有文件和目录权限赋给 haowen ,-R 包括子目录) chgrp -R mysql . (把当前文件夹变更到mysql群组,mysql是已经有的群组)变更文件或目录的所属群组。 umask 档案预设权限: umask 指定的是『该默认值需要减掉的权限 !』 chattr (设定档案隐藏属性) lsattr (显示档案隐藏属性) find ( find ./ -name file1 -print ,从当前目录向下查找名为 file1 的文件) mkdir ( mkdir dir1 ,新建目录 dir1 ) mkdir [-mp] 目录名称 参数: -m :设定档案的权限喔!直接设定,不需要看预设权限 (umask) 的脸色~ -p :帮助你直接将所需要的目录递归建立起来! [root@linux ~]# rmdir [-p] 目录名称 参数: -p :连同上层『空的』目录也一起删除 pwd Print Working Directory ( pwd ,显示当前路径 ) pwd -P 显示出确实的路径,而非使用连接(link)路径 cd ( cd /usr/local/ 进入目录 /usr/local/ , cd ../ 返回到上一级目录 ./ 当前目录 ../父目录 - 代表前一个工作目录 ~代表[目前使用者身份]所在的家目录 ~account代表account这个使用者的家目录)针对 cd 的使用方法,如果仅输入 cd 时,代表的就是『 cd ~ 』 mv ( mv file1 /home/haowen/ ,将文件移动到目录 /home/haowen/下 ,相当于 window 剪切 ) ( mv file1 filenew1 ,将文件名改为 filenew1 ) [root@linux ~]# mv [-fiu] source destination [root@linux ~]# mv [options] source1 source2 source3 .... directory 参数: -f :force 强制的意思,强制直接移动而不询问; -i :若目标档案 (destination) 已经存在时,就会询问是否覆盖! -u :若目标档案已经存在,且 source 比较新,才会更新 (update) cp ( cp file1 /home/haowen/ ,将文件复制copy到目录 /home/haowen/下 cp -r dir1 /home/haowen/ cp file1 ./file2 复制文件并改名) [root@linux ~]# cp [-adfilprsu] 来源档(source) 目的檔(destination) [root@linux ~]# cp [options] source1 source2 source3 .... directory 参数: -a :相当于 -pdr 的意思; -d :若来源文件为连结文件的属性(link file),则复制连结文件属性而非档案本身; -f :为强制 (force) 的意思,若有重复或其它疑问时,不会询问使用者,而强制复制; -i :若目的檔(destination)已经存在时,在覆盖时会先询问是否真的动作! -l :进行硬式连结 (hard link) 的连结档建立,而非复制档案本身; -p :连同档案的属性一起复制过去,而非使用预设属性; -r :递归持续复制,用于目录的复制行为; -s :复制成为符号连结文件 (symbolic link),亦即『快捷方式』档案; -u :若 destination 比 source 旧才更新 destination ! rm ( rm file1 ,rm -r dir1,rm -rf dir2 删除文件或目录, f不提示输入y [root@linux ~]# rm [-fir] 档案或目录 参数: -f :就是 force 的意思,强制移除; -i :互动模式,在删除前会询问使用者是否动作 -r :递归删除啊!最常用在目录的删除了 touch 建立一个空的档案,将某个档案日期修订为目前 (mtime 与 atime) [root@linux ~]# touch [-acdmt] 档案 参数: -a :仅修订 access time; -c :仅修改时间,而不建立档案; -d :后面可以接日期,也可以使用 --date="日期或时间" -m :仅修改 mtime ; -t :后面可以接时间,格式为[YYMMDDhhmm] file 如果你想要知道某个档案的基本数据,例如是属于 ASCII 或者是 data 档案,或者是 binary , 且其中有没有使用到动态函式库 (share library) 等等的信息,就可以利用 file 这个指令来检阅喔! which (寻找『执行档』) 这个指令是根据『PATH』这个环境变量所规范的路径,去搜寻『执行档』的档名 [root@linux ~]# which [-a] command 参数: -a :将所有可以找到的指令均列出,而不止第一个被找到的指令名称 whereis (从数据库寻找特定档案) [root@linux ~]# whereis [-bmsu] 档案或目录名 参数: -b :只找 binary 的档案 -m :只找在说明文件 manual 路径下的档案 -s :只找 source 来源档案 -u :没有说明档的档案! 功能说明:计算字数。 语 法:wc [-clw][--help][--version][文件名] 补充说明:利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定任何文件名称,或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。假设不给予其参数,wc指令会一并显示列数、字数和Byte数 参 数: -c 只显示Byte数,亦即字符数; -l 只显示列数; -w 只显示字数; -m 同样显示字符数 --help 在线帮助; --version 显示此软件的版本信息。 locate 从数据库列出某个档案的完整档名 find ./ -name index.jsp 查找当前目录下名称为index.jsp的文件 grep ( grep "mobile=13712345678" logfile1 ,在logfile1中 搜索查找内容 "mobile=13712345678" ) ping ( ping 61.129.78.9 ,ping www.163.com ,测试网络连接是否正常 ) ifconfig ( ifconfig ,查看本机 IP地址,子网掩码等 ) ps ( ps aux 查看系统中已经启动的进程, ps aux | grep programe1 , 查看程序1是否正在运行 kill ( kill -9 2325 ,杀死进程号为 2325的进程, killall programe1 ,杀死programe1进程 ) reboot ( 重启系统 ) init 0 ( 关机 ,仅 root 用户有权操作 ) init 6 ( 重启系统 ,仅 root 用户有权操作 ) gzip ( gzip file1 ,压缩文件 file1 ) gunzip ( gunzip file1.gz 解压缩文件 file1.gz ) tar -zcvf ( tar -zcvf dir1.tar.gz ./dir1 ,将当前目录下 dir1目录所有内容 压缩打包,包名dir1.tar.gz ) tar -zxvf ( tar -zxvf dir1.tar.gz ,解开压缩包 ) echo "hello!" >> file1 ( 将 "hello" 添加到文件 file1后面, 当 file1 不存在就创建 file1 vi file2 ( vi 编即器新建文件 file2) ...输入内容 welcome.. ( 按 i 进入 insert 状态 即插入模式 ,按 Esc 退出插入模式 在非插入模式下按 dd 删除光标当前行,按 x 删除当前字, 按 j,n,l移动光标 ) :wq ( 保存退出 ) :q! (不保存退出)增加环境变量
[root@linux ~]# echo $PATH [root@linux ~]# PATH="$PATH":/root env 显示系统的一些环境变量 set 显示系统的所有变量 chmod: Linux/Unix 的档案调用权限分为三级 : 档案拥有者、群组、其他。 利用 chmod 可以藉以控制档案如何被他人所调用。 + 表示增加权限、- 表示取消权限、= 表示唯一设定权限。 r 表示可读取,w 表示可写入,x 表示可执行, 1. 将档案 file1.txt 设为所有人皆可读取 : chmod ugo+r file1.txt 或 chmod 444 file1.txt 2. 将文件 file2 设为属主可读写执行,Group,other ,只能读 chmod 744 file2 ( 7=> "111" ,4=>"100" 二进制 ) 3. 将文件 file3 设为属主可读写执行,Group,other ,无权限操作不能读写执行) chmod 700 file3 ( 7=> "111" ,0=>"000" ) 其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。 r=4,w=2,x=1 若要rwx属性则4+2+1=7; 若要rw-属性则4+2=6; 若要r-x属性则4+1=5 tar: tar 调用gzip gzip是GNU组织开发的一个压缩程序,.gz结尾的文件就是gzip压缩的结果。 与gzip相对的解压程序是gunzip。tar中使用-z这个参数来调用gzip。 # tar -czf all.tar.gz *.jpg 这条命令是将所有.jpg的文件打成一个tar包,并且将其用gzip压缩,生成一个 gzip压缩过的包,包名为all.tar.gz # tar -xzf all.tar.gz 这条命令是将上面产生的包解开。 date 显示日期的指令: cal 显示日历的指令: bc 简单好用的计算器: [Tab] 按键 (按两次) 命令补全: [Ctrl]-c 按键 中断目前程序: [Ctrl]-d 按键 (相当于输入 exit) 键盘输入结束: info 在线求助 : who 要看目前有谁在在线: finger 显示关于系统用户的信息 netstat -a 看网络的联机状态: ntsysv 设置服务随系统启动时同时启动 shutdown ,shutdown -h now 惯用的关机指令: reboot, halt, poweroff 重新开机,关机:--- 系统相关的命令:---
dmesg : 例如 dmesg | more 显示系统的诊断信息,操作系统版本号,物理内及其它信息 df : 例如 df -h 显示硬盘空间 du : 查看目录中各级子目录使用的硬盘空间 free: 查看系统内存,虚拟内存(交换空间)的大小占用情况 top: 动态实时查看系统内存,CPU,进程 hostname 查看主机名: hostname 新主机名 修改主机名(临时的,重启就没了): man 命令:查看该命令的基础用法 info 命令:查看该命令的基础用法 ls -l /lib/modules/`uname -r`/kernel/fs 查看Linux 支持的档案系统有哪些 cat /proc/filesystems 查看Linux目前已启用的档案系统 type 查询某个指令是来自于外部指令(指的是其它非 bash 套件所提供的指令) 或是内建在 bash 当中的指令 [root@linux ~]# type [-tpa] name 参数: :不加任何参数时,则 type 会显示出那个 name 是外部指令还是 bash 内建的指令! -t :当加入 -t 参数时,type 会将 name 以底下这些字眼显示出他的意义: file :表示为外部指令; alias :表示该指令为命令别名所设定的名称; builtin :表示该指令为 bash 内建的指令功能; -p :如果后面接的 name 为指令时,会显示完整文件名(外部指令)或显示为内建指令; -a :会将由 PATH 变量定义的路径中,将所有含有 name 的指令都列出来,包含 alias myname=pqb 变量的设定 PATH="$PATH":/home/dmtsai/bin 变量的累加 echo $myname 变量的查看 unset myname 变量的取消 在来看看关机,关闭系统使用Shutdown命令,确保用户和系统的资料完整。只有root用户才能使用这个命令。 一般的用户是不允许执行这个命令的。 我们先看看showdown语法: shutdown [options] when [message] options: -r 表示重启,-h表示系统服务停滞(halt)后,立刻关机,-f表示快速重启 when: 为shutdown指定时间。hh:mm:绝对时间,hh指小时,mm指分钟;如08:30,+m:m分钟后执行, now=+0,也就是立刻执行 message:表示系统的广播信息,一般提示各个用户系统关机或重启,要求用户保存资料后退出。 我们来看看几个例子: shutdown -h now 立刻关机 shutdown -h 21:30 今天21:30关机 shutdown -h +10 十分钟后关机 shutdown -r now 立刻重启 shutdown -r +10 ‘the system will reboot’ 10分钟后重启,管理员提示用户系统要重启了,便于用户保存工 作中的资料。只有root用户才能使用这个命令。 创建文件 创建文件是指创建一个一般的普通文件,并且这个文件为空,我们可以使 用touch命令来建立一般文件,如下操作: [root@Linux two]# touch 111.txt 搜索文件 我们先来学习一下如何搜索文件,特别是刚开始学习Linux的时候,自己建立的文件不知道放在哪里了,常有发 生。如果知道文件名,却不知道文件在那个目录下面了,我们就可以使用locate命令来搜索文件。看如下操作 : [root@Linux one]# locate install.log /root/install.log /root/install.log.syslog 看一下,我们一下就搜索了两个与install.log相关的文件,他们都在/root目录下,同时我们感觉到,使用这个命 令搜索文件的速度比较快,其实要使用这个命令,必须配合数据库来使用,因为这个命令是从数据库中来搜索 文件,这个数据库的更新速度是7天更新一次。如下操作: [root@Linux one]# touch 001.txt [root@Linux one]# locate 001.txt 发现这个命令找不到新建立的文件,所以我们要使用这个命令搜索文件之前,必须自己更新一下数据库(更新数据库需要root权限),如下 操作: [root@Linux one]# updatedb [root@Linux one]# locate 001.txt /root/one/001.txt 看看,如果执行updatedb这个命令更新数据库之后,我们就可以找到我们所需要的数据。不过更新数据库的时 间需要一段时间。 locale能看语言环境 保存语言信息的文件在/etc/sysconfig/i18n中。 /sbin/service xinetd restart|start|stop 启动后台服务, /sbin/chkconfig --list |more 显示系统服务启动情况,显示了运行级别0到运行级别6的情况. 这些服务都是靠系统脚本init启动的。还有一些不是靠系统脚本启动的而下面会看到一些特殊服务,他们不是 靠init 启动的。是靠xinetd启动的,是一个独立的互联网服务器的服务器是一个超级服务其,可以启动很多的子服 务器。 大家看到 xinetd这个服务只要他是开启的,就可以运行他下面的服务器,它下面的大部分都是关闭的,只 有一个是开启的,如果我们想开启一个服务可以使用chkconfig命令,例如我们想开启 rsync服务,我们可以使 用chkconfig rsync on|off 命令。 mount 在mount命令不使用任何选项和参数的时候将显示当前linux系统中以挂载的文件系统信息。 mount Cttype dev dir 光盘文件系统类型是:iso9660;dev表示需要挂载文件系统的设备名称,光盘驱动器的设备名称是/dev/cdrom; dir表示挂载点,即挂载到的文件目录路径。 首先介绍光盘的挂载方法: mount -t iso9660 /dev/cdrom /media/cdrom 列出系统中所有存储设备 fdisk -l命令 使用“vfat”文件系统类型表示所有的fat文件系统类型,包括fat16和fat32,ntfs还是使用ntfs表示。 u盘的挂载方法 mount -t vfat /dev/sdb1 /mnt/ mount -t ntfs /dev/sdb1 /mnt/ umount命令用于卸载已经挂载的文件系统,基本格式如:umount dir device 对于光盘文件系统的卸载可以使用,以下两条命令中的任意一条 umount /dev/cdrom umount /media/cdrom u盘的卸载 umount /dev/sdb1 eject命令 eject 弹出光盘命令 eject -t 光盘驱动器自动回收 cut 使用权限:所有使用者 用法:cut -cnum1-num2 filename 说明:显示每行从开头算起 num1 到 num2 的文字。 范例: shell>> cat example test2 this is test1 shell>> cut -c0-6 example 开头算起前 6 个字元 test2 this i 指令名称:ln 使用权限:所有使用者 使用方式:ln [options] source dist,其中 option 的格式为: [-bdfinsvF] [-S backup-suffix] [-V {numbered,existing,simple}] [--help] [--version] [--] 说明:Linux/Unix 档案系统中,有所谓的连结(link),我们可以将其视为档案的别名,而连结又可分为两种:硬连结(hard link)与软连结(symbolic link),硬连结的意思是一个档案可以有多个名称,而软连结的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。硬连结是存在同一个档案系统中,而软连结却可以跨越不同的档案系统。 ln source dist 是产生一个连结(dist)到 source,至于使用硬连结或软链结则由参数决定。 不论是硬连结或软链结都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。 -f:链结时先将与 dist 同档名的档案删除-d:允许系统管理者硬链结自己的目录-i:在删除与 dist 同档名的档案时先进行询问-n:在进行软连结时,将 dist 视为一般的档案-s:进行软链结(symbolic link)-v:在连结之前显示其档名-b:将在链结时会被覆写或删除的档案进行备份-S SUFFIX:将备份的档案都加上 SUFFIX 的字尾-V METHOD:指定备份的方式--help:显示辅助说明--version:显示版本 范例: 将档案 yy 产生一个 symbolic link:zz ln -s yy zz 将档案 yy 产生一个 hard link:zz ln yy xx 名称:at 使用权限:所有使用者 使用方式:at -V [-q queue] [-f file] [-mldbv] TIME 说明:at 可以让使用者指定在 TIME 这个特定时刻执行某个程式或指令,TIME 的格式是 HH:MM其中的 HH 为小时,MM 为分钟,甚至你也可以指定 am, pm, midnight, noon, teatime(就是下午 4 点锺)等口语词。 如果想要指定超过一天内的时间,则可以用 MMDDYY 或者 MM/DD/YY 的格式,其中 MM 是分钟,DD 是第几日,YY 是指年份。另外,使用者甚至也可以使用像是 now + 时间间隔来弹性指定时间,其中的时间间隔可以是 minutes, hours, days, weeks 另外,使用者也可指定 today 或 tomorrow 来表示今天或明天。当指定了时间并按下 enter 之后,at 会进入交谈模式并要求输入指令或程式,当你输入完后按下 ctrl+D 即可完成所有动作,至于执行的结果将会寄回你的帐号中。 把计: -V:印出版本编号 -q:使用指定的伫列(Queue)来储存,at 的资料是存放在所谓的 queue 中,使用者可以同时使用多个 queue,而 queue 的编号为 a, b, c... z 以及 A, B, ... Z 共 52 个 -m:即使程式/指令执行完成后没有输出结果, 也要寄封信给使用者 -f file:读入预先写好的命令档。使用者不一定要使用交谈模式来输入,可以先将所有的指定先写入档案后再一次读入 -l:列出所有的指定 (使用者也可以直接使用 atq 而不用 at -l) -d:删除指定 (使用者也可以直接使用 atrm 而不用 at -d) -v:列出所有已经完成但尚未删除的指定 例子: 三天后的下午 5 点锺执行 /bin/ls: at 5pm + 3 days /bin/ls 三个星期后的下午 5 点锺执行 /bin/ls: at 5pm + 2 weeks /bin/ls 明天的 17:20 执行 /bin/date: at 17:20 tomorrow /bin/date 1999 年的最后一天的最后一分钟印出 the end of world ! at 23:59 12/31/1999 echo the end of world ! 名称:cal 使用权限:所有使用者 使用方式:cal [-mjy] [month [year]] 说明: 显示日历。若只有一个参数,则代表年份(1-9999),显示该年的年历。年份必须全部写出:``cal 89\ 将不会是显示 1989 年的年历。使用两个参数,则表示月份及年份。若没有参数则显示这个月的月历。 1752 年 9 月第 3 日起改用西洋新历,因这时大部份的国家都采用新历,有 10 天被去除,所以该月份的月历有些不同。在此之前为西洋旧历。 匡兜: -m:以星期一为每周的第一天方式显示。 -j:以凯撒历显示,即以一月一日起的天数显示。 -y:显示今年年历。 范例: cal:显示本月的月历。 [root@mylinux /root]# date Tue Aug 15 08:00:18 CST 2000 [root@mylinux /root]# cal ... cal 2001:显示公元 2001 年年历。 [root@mylinux /root]# cal 2001 ... cal 5 2001:显示公元 2001 年 5 月月历。 [root@mylinux /root]# cal 5 2001 名称:crontab 使用权限:所有使用者 使用方式: crontab [ -u user ] filecrontab [ -u user ] { -l | -r | -e } 说明: crontab 是用来让使用者在固定时间或固定间隔执行程式之用,换句话说,也就是类似使用者的时程表。-u user 是指设定指定 user 的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。如果不使用 -u user 的话,就是表示设定自己的时程表。 参数: -e:执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe) -r:删除目前的时程表 -l:列出目前的时程表 时程表的格式如下: f1 f2 f3 f4 f5 program 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程式。 当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程式,其余类推 当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其余类推 当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其余类推 当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其余类推 使用者也可以将所有的设定先存放在档案 file 中,用 crontab file 的方式来设定时程表。 例子: 每月每天每小时的第 0 分钟执行一次 /bin/ls: 0 7 * * * /bin/ls 在 12 月内, 每天的早上 6 点到 12 点中,每隔 20 分钟执行一次 /usr/bin/backup: 0 6-12/3 * 12 * /usr/bin/backup 周一到周五每天下午 5:00 寄一封信给 alex@domain.name: 0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata 每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha" 20 0-23/2 * * * echo "haha" 注意: 当程式在你所指定的时间执行后,系统会寄一封信给你,显示该程式执行的内容,若是你不希望收到这样的信,请在每一行空一格之后加上 > /dev/null 2>&1 即可。 名称:sleep 使用权限:所有使用者 使用方式:sleep [--help] [--version] number[smhd] 说明:sleep 可以用来将目前动作延迟一段时间 参数说明: --help:显示辅助讯息 --version:显示版本编号 number:时间长度,后面可接 s,m,h 或 d 其中 s 为秒,m 为 分钟,h 为小时,d 为日数 例子: 显示目前时间后延迟 1 分钟,之后再次显示时间: date;sleep 1m;date 名称: finger 使用权限: 所有使用者 使用方式: finger [options] user[@address] 说明:finger 可以让使用者查询一些其他使用者的资料。 范例:下列指令可以查询本机管理员的资料: finger root 名称:last 使用权限:所有使用者 使用方式:shell>> last [options] 说明:显示系统开机以来获是从每月初登入者的讯息 把计: -R 省略 hostname 的栏位 -num 展示前 num 个 username 展示 username 的登入讯息 tty 限制登入讯息包含终端机代号 范例: shell>> last -R -2 名称:write 使用权限:所有使用者 使用方式: write user [ttyname] 说明:传讯息给其他使用者 把计: user:预备传讯息的使用者帐号 ttyname:如果使用者同时有两个以上的 tty 连线,可以自行选择合适的 tty 传讯息 例子.1: 传讯息给 Rollaend,此时 Rollaend 只有一个连线: write Rollaend 接下来就是将讯息打上去,结束请按 ctrl+c 例子.2 :传讯息给 Rollaend,Rollaend 的连线有 pts/2,pts/3: write Rollaend pts/2 接下来就是将讯息打上去,结束请按 ctrl+c 注意:若对方设定 mesg n,则此时讯席将无法传给对方 名称:expr 使用权限:所有使用者 ### 字串长度 shell>> expr length "this is a test" 14 ### 数字商数 shell>> expr 14 % 9 5 ### 从位置处抓取字串 shell>> expr substr "this is a test" 3 5 is is ### 数字串 only the first character shell>> expr index "testforthegame" e 2 ### 字串真实重现 shell>> expr quote thisisatestformela thisisatestformela 指令:clear 用途:清除萤幕用。 使用方法:在 console 上输入 clear。
TOP命令
查看多核CPU命令mpstat -P ALL 和 sar -P ALL
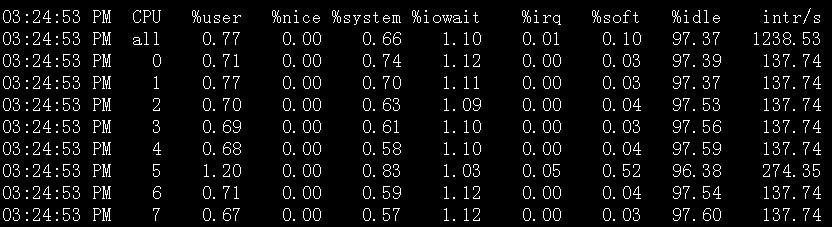
说明:sar -P ALL > aaa.txt 重定向输出内容到文件 aaa.txt
top命令经常用来监控linux的系统状况,比如cpu、内存的使用,程序员基本都知道这个命令,但比较奇怪的是能用好它的人却很少,例如top监控视图中内存数值的含义就有不少的曲解。
本文通过一个运行中的WEB服务器的top监控截图,讲述top视图中的各种数据的含义,还包括视图中各进程(任务)的字段的排序。
top进入视图
top视图 01
【top视图 01】是刚进入top的基本视图,我们来结合这个视图讲解各个数据的含义。
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:530668+79236+4231276 = 4.7GB。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第七行以下:各进程(任务)的状态监控 PID — 进程id USER — 进程所有者 PR — 进程优先级 NI — nice值。负值表示高优先级,正值表示低优先级 VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA SHR — 共享内存大小,单位kb S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 %CPU — 上次更新到现在的CPU时间占用百分比 %MEM — 进程使用的物理内存百分比 TIME+ — 进程使用的CPU时间总计,单位1/100秒 COMMAND — 进程名称(命令名/命令行)
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。
进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,在【top视图 01】中进程ID为14210的java进程排在第一(cpu占用100%),进程ID为14183的java进程排在第二(cpu占用12%)。可通过键盘指令来改变排序字段,比如想监控哪个进程占用MEM最多,我一般的使用方法如下:1. 敲击键盘“b”(打开/关闭加亮效果)。
我们发现进程id为10704的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
2. 敲击键盘“x”(打开/关闭排序列的加亮效果)。
可以看到,top默认的排序列是“%CPU”。
3. 通过”shift + >”或”shift + <”可以向右或左改变排序列。
视图现在已经按照%MEM来排序了。
改变进程显示字段
1. 敲击“f”键,top进入另一个视图,在这里可以编排基本视图中的显示字段:
这里列出了所有可在top基本视图中显示的进程字段,有”*”并且标注为大写字母的字段是可显示的,没有”*”并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
2. “回车”返回基本视图,可以看到多了“CODE”和“DATA”两个字段:
top命令的补充
top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。监控java线程数:
ps -eLf | grep java | wc -l监控网络客户连接数:
//
vim详细使用介绍 命令大全
vim的基本概念
基本上vim可以分为三种状态,分别是命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下: 1) 命令行模式command mode) 控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode。 2) 插入模式(Insert mode) 只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。 3) 底行模式(last line mode) 将文件保存或退出vim,也可以设置编辑环境,如寻找字符串、列出行号……等。 不过一般我们在使用时把vim简化成两个模式,就是将底行模式(last line mode)也算入命令行模式command mode)。在使用「last line mode」之前,请记住先按「ESC」键确定您已经处于「command mode」下后,再按「:」冒号即可进入「last line mode」。
A) 列出行号 「set nu」:输入「set nu」后,会在文件中的每一行前面列出行号。 B) 跳到文件中的某一行 「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。 C) 查找字符 「/关键字」:先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往后寻找到您要的关键字为止。 「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往前寻找到您要的关键字为止。 D) 保存文件 「w」:在冒号输入字母「w」就可以将文件保存起来。 E) 离开vim 「q」:按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。 「qw」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。
vim命令:
:q 退出
:q! 强制退出
:wq 保存并退出
:set number 显示行号
:set nonumber 隐藏行号
/apache 在文档中查找apache 按n跳到下一个,shift+n上一个
yyp 复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)
进入vim的命令
vim filename :打开或新建文件,并将光标置于第一行首 vim +n filename :打开文件,并将光标置于第n行首 vim + filename :打开文件,并将光标置于最后一行首 vim +/pattern filename:打开文件,并将光标置于第一个与pattern匹配的串处 vim -r filename :在上次正用vi编辑时发生系统崩溃,恢复filename vim filename....filename :打开多个文件,依次进行编辑移动光标类命令
vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、「l」,分别控制光标左、下、上、右移一格。
按数字「0」:移到文章的开头。 按「G」:移动到文章的最后。 按「$」:移动到光标所在行的“行尾”。 按「^」:移动到光标所在行的“行首” 按「w」:光标跳到下个字的开头 按「e」:光标跳到下个字的字尾 按「b」:光标回到上个字的开头 按「#l」:光标移到该行的第#个位置,如:5l,56l。 h :光标左移一个字符 l :光标右移一个字符 space:光标右移一个字符 Backspace:光标左移一个字符 k或Ctrl+p:光标上移一行 j或Ctrl+n :光标下移一行 Enter :光标下移一行 w或W :光标右移一个字至字首 b或B :光标左移一个字至字首 e或E :光标右移一个字至字尾 ) :光标移至句尾 ( :光标移至句首 }:光标移至段落开头 {:光标移至段落结尾 nG:光标移至第n行首 n+:光标下移n行 n-:光标上移n行 n$:光标移至第n行尾 H :光标移至屏幕顶行 M :光标移至屏幕中间行 L :光标移至屏幕最后行 0:(注意是数字零)光标移至当前行首 $:光标移至当前行尾屏幕翻滚类命令
按「ctrl」+「b」:屏幕往“后”移动一页。
按「ctrl」+「f」:屏幕往“前”移动一页。 按「ctrl」+「u」:屏幕往“后”移动半页。 按「ctrl」+「d」:屏幕往“前”移动半页。Ctrl+u:向文件首翻半屏
Ctrl+d:向文件尾翻半屏 Ctrl+f:向文件尾翻一屏 Ctrl+b;向文件首翻一屏 nz:将第n行滚至屏幕顶部,不指定n时将当前行滚至屏幕顶部。
插入文本类命令
按「i」切换进入插入模式「insert mode」,按“i”进入插入模式后是从光标当前位置开始输入文件;
按「a」进入插入模式后,是从目前光标所在位置的下一个位置开始输入文字; 按「o」进入插入模式后,是插入新的一行,从行首开始输入文字。 i :在光标前 I :在当前行首 a:光标后 A:在当前行尾 o:在当前行之下新开一行 O:在当前行之上新开一行 r:替换当前字符 R:替换当前字符及其后的字符,直至按ESC键 s:从当前光标位置处开始,以输入的文本替代指定数目的字符 S:删除指定数目的行,并以所输入文本代替之 ncw或nCW:修改指定数目的字 nCC:修改指定数目的行
删除文本命令
「x」:每按一次,删除光标所在位置的“后面”一个字符。
「#x」:例如,「6x」表示删除光标所在位置的“后面”6个字符。 「X」:大写的X,每按一次,删除光标所在位置的“前面”一个字符。 「#X」:例如,「20X」表示删除光标所在位置的“前面”20个字符。 「dd」:删除光标所在行。 「#dd」:从光标所在行开始删除#行 ndw或ndW:删除光标处开始及其后的n-1个字 do:删至行首 d$:删至行尾 ndd:删除当前行及其后n-1行 x或X:删除一个字符,x删除光标后的,而X删除光标前的 Ctrl+u:删除输入方式下所输入的文本
复制粘贴文本命令
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。 「#yw」:复制#个字到缓冲区 「yy」:复制光标所在行到缓冲区。 「#yy」:例如,「6yy」表示拷贝从光标所在的该行“往下数”6行文字。 「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与“y”有关的复制命令都必须与“p”配合才能完成复制与粘贴功能。 "?nyy:将当前行及其下n行的内容保存到寄存器?中,其中?为一个字母,n为一个数字 "?nyw:将当前行及其下n个字保存到寄存器?中,其中?为一个字母,n为一个数字 "?nyl:将当前行及其下n个字符保存到寄存器?中,其中?为一个字母,n为一个数字 "?p:取出寄存器?中的内容并将其放到光标位置处。这里?可以是一个字母,也可以是一个数字 ndd:将当前行及其下共n行文本删除,并将所删内容放到1号删除寄存器中。
恢复上一次操作
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次“u”可以执行多次恢复。查找命令
/pattern:从光标开始处向文件尾搜索pattern ?pattern:从光标开始处向文件首搜索pattern n:在同一方向重复上一次搜索命令 N:在反方向上重复上一次搜索命令「/关键字」:先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往后寻找到您要的关键字为止。
「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往前寻找到您要的关键字为止。替换命令
「r」:替换光标所在处的字符。 「R」:替换光标所到之处的字符,直到按下「ESC」键为止。 :s/p1/p2/g:将当前行中所有p1均用p2替代 :n1,n2s/p1/p2/g:将第n1至n2行中所有p1均用p2替代 :g/p1/s//p2/g:将文件中所有p1均用p2替换
更改光标文本
「cw」:更改光标所在处的字到字尾处 「c#w」:例如,「c3w」表示更改3个字
跳至指定的行
「ctrl」+「g」列出光标所在行的行号。 「#G」:例如,「15G」,表示移动光标至文章的第15行行首。「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入:15,再回车,就会跳到文章的第15行。
选项设置
all:列出所有选项设置情况 term:设置终端类型 ignorance:在搜索中忽略大小写 list:显示制表位(Ctrl+I)和行尾标志($) number:显示行号 「set nu」:输入「set nu」后,会在文件中的每一行前面列出行号。report:显示由面向行的命令修改过的数目 terse:显示简短的警告信息 warn:在转到别的文件时若没保存当前文件则显示NO write信息 nomagic:允许在搜索模式中,使用前面不带“\”的特殊字符 nowrapscan:禁止vim在搜索到达文件两端时,又从另一端开始 mesg:允许vim显示其他用户用write写到自己终端上的信息最后行方式命令
:n1,n2 co n3:将n1行到n2行之间的内容拷贝到第n3行下 :n1,n2 m n3:将n1行到n2行之间的内容移至到第n3行下 :n1,n2 d :将n1行到n2行之间的内容删除 :w :保存当前文件 :e filename:打开文件filename进行编辑 :x:保存当前文件并退出 :q:退出vim :q!:不保存文件并退出vim :!command:执行shell命令command :n1,n2 w!command:将文件中n1行至n2行的内容作为command的输入并执行之,若不指定n1,n2,则表示将整个文件内容作为command的输入 :r!command:将命令command的输出结果放到当前行VIM常用技巧
VIM命令可以说是Unix/Linux世界里最常用的编辑文件的命令了,但是因为它的命令集众多,很多人都不习惯使用它,其实您只需要掌握基本命令,然后加以灵活运用,就会发现它的优势,并会逐渐喜欢使用这种方法。本文旨在介绍VIM的一些最常用命令和高级应用技巧。 常见问题及应用技巧在一个新文件中读/etc/passwd中的内容,取出用户名部分。
---- vim file
---- :r /etc/passwd 在打开的文件file中光标所在处读入/etc/passwd ---- :%s/:.*//g 删除/etc/passwd中用户名后面的从冒号开始直到行尾的所有部分。 ---- 您也可以在指定的行号后读入文件内容,例如使用命令“:3r /etc/passwd”从新文件的第3行开始读入 /etc/passwd的所有内容。 ---- 我们还可以使用以下方法删掉文件中所有的空行及以#开始的注释行。 ---- #cat squid.conf.default | grep -v ^$ | grep -v ^#
在打开一个文件编辑后才知道登录的用户对该文件没有写的权限,不能存盘,需要将所做修改存入临时文件。
---- vim file ---- :w /tmp/1 保存所做的所有修改,也可以将其中的某一部分修改保存到临时文件,例如仅仅把第20~59行之间的内容存盘成文件/tmp/1,我们可以键入如下命令。 ---- vim file ---- :20,59w /tmp/1用VIM编辑一个文件,但需要删除大段的内容。
---- 首先利用编辑命令“vim file”打开文件,然后将光标移到需要删除的行处按Ctrl+G显示行号,再到结尾处再按Ctrl+G,显示文件结尾的行号。---- :23,1045d 假定2次得到的行号为23和1045,则把这期间的内容全删除,也可以在要删除的开始行和结束行中用ma、mb命令标记,然后利用“:a,bd”命令删除。在整个文件的各行或某几行的行首或行尾加一些字符串。
---- vim file ---- :3,$s/^/some string / 在文件的第一行至最后一行的行首插入“some string”。 ---- :%s/$/some string/g 在整个文件每一行的行尾添加“some string”。 ---- :%s/string1/string2/g 在整个文件中替换“string1”成“string2”。 ---- :3,7s/string1/string2/ 仅替换文件中的第3行到第7行中的“string1”成“string2”。 ---- 注意: 其中s为substitute,%表示所有行,g表示global。
同时编辑2个文件,拷贝一个文件中的文本并粘贴到另一个文件中。
---- vim file1 file2 ---- yy 在文件1的光标处拷贝所在行 ---- :n 切换到文件2 (n=next) ---- p 在文件2的光标所在处粘贴所拷贝的行 ---- :n 切换回文件1替换文件中的路径。
---- 使用命令“:%s#/usr/bin#/bin#g”可以把文件中所有路径/usr/bin换成/bin。也可以使用命令“:%s//usr/bin//bin/g”实现,其中“”是转义字符,表明其后的“/”字符是具有实际意义的字符,不是分隔符。
vim命令列表
1) 下表列出命令模式下的一些键的功能:
h左移光标一个字符 l右移光标一个字符 k光标上移一行 j光标下移一行 ^光标移动至行首 0数字“0”,光标移至文章的开头 G光标移至文章的最后 $光标移动至行尾 Ctrl+f向前翻屏 Ctrl+b向后翻屏 Ctrl+d向前翻半屏 Ctrl+u向后翻半屏 i在光标位置前插入字符 a在光标所在位置的后一个字符开始增加 o插入新的一行,从行首开始输入 ESC从输入状态退至命令状态 x删除光标后面的字符 #x删除光标后的#个字符 X(大写X),删除光标前面的字符 #X删除光标前面的#个字符 dd删除光标所在的行 #dd删除从光标所在行数的#行 yw复制光标所在位置的一个字 #yw复制光标所在位置的#个字 yy复制光标所在位置的一行 #yy复制从光标所在行数的#行 p粘贴 u取消操作 cw更改光标所在位置的一个字 #cw更改光标所在位置的#个字2) 下表列出行命令模式下的一些指令
w filename储存正在编辑的文件为filename wq filename储存正在编辑的文件为filename,并退出vim q!放弃所有修改,退出vim set nu显示行号 /或?查找,在/后输入要查找的内容 n与/或?一起使用,如果查找的内容不是想要找的关键字,按n或向后(与/联用)或向前(与?联用)继续查找,直到找到为止。
///
gdb常用命令
调用gdb编译需要在cc后面加 -g参数再加-o;
[root@redhat home]#gdb 调试文件:启动gdb
(gdb) l :(字母l)从第一行开始列出源码
(gdb) break n :在第n行处设置断点
(gdb) break func:在函数func()的入口处设置断点
(gdb) info break: 查看断点信息
(gdb) r:运行程序
(gdb) n:单步执行
(gdb) c:继续运行
(gdb) p 变量 :打印变量的值
(gdb) bt:查看函数堆栈
(gdb) finish:退出函数
(gdb) shell 命令行:执行shell命令行
(gdb) set args 参数:指定运行时的参数
(gdb) show args:查看设置好的参数
(gdb) show paths:查看程序运行路径;
set environment varname [=value] 设置环境变量。如:set env USER=hchen;
show environment [varname] 查看环境变量;
(gdb) cd 相当于shell的cd;
(gdb)pwd :显示当前所在目录
(gdb)info program: 来查看程序的是否在运行,进程号,被暂停的原因。
(gdb)clear 行号n:清除第n行的断点
(gdb)delete 断点号n:删除第n个断点
(gdb)disable 断点号n:暂停第n个断点
(gdb)enable 断点号n:开启第n个断点
(gdb)step:单步调试如果有函数调用,则进入函数;与命令n不同,n是不进入调用的函数的
list :简记为 l ,其作用就是列出程序的源代码,默认每次显示10行。
list 行号:将显示当前文件以“行号”为中心的前后10行代码,如:list 12 list 函数名:将显示“函数名”所在函数的源代码,如:list main list :不带参数,将接着上一次 list 命令的,输出下边的内容。 注意 :如果运行list 命令得到类似如下的打印,那是因为在编译程序时没有加入 -g 选项: (gdb) list 1 ../sysdeps/i386/elf/start.S: No such file or directory. in ../sysdeps/i386/elf/start.Srun:简记为 r ,其作用是运行程序,当遇到断点后,程序会在断点处停止运行,等待用户输入下一步的命令。
回车:重复上一条命令。 set args:设置运行程序时的命令行参数,如:set args 33 55 show args:显示命令行参数 continue:简讯为 c ,其作用是继续运行被断点中断的程序。 break:为程序设置断点。 break 行号:在当前文件的“行号”处设置断点,如:break 33 break 函数名:在用户定义的函数“函数名”处设置断点,如:break cb_button info breakpoints:显示当前程序的断点设置情况 disable breakpoints Num:关闭断点“Num”,使其无效,其中“Num”为 info breakpoints 中显示的对应值 enable breakpoints Num:打开断点“Num”,使其重新生效 step:简记为 s ,单步跟踪程序,当遇到函数调用时,则进入此函数体(一般只进入用户自定义函数)。 next:简记为 n,单步跟踪程序,当遇到函数调用时,也不进入此函数体;此命令同 step 的主要区别是,step 遇到用户自定义的函数,将步进到函数中去运行,而 next 则直接调用函数,不会进入到函数体内。 until:当你厌倦了在一个循环体内单步跟踪时,这个命令可以运行程序直到退出循环体。 finish: 运行程序,直到当前函数完成返回,并打印函数返回时的堆栈地址和返回值及参数值等信息。 stepi或nexti:单步跟踪一些机器指令。print 表达式:简记为 p ,其中“表达式”可以是任何当前正在被测试程序的有效表达式,比如当前正在调试C语言的程序,那么“表达式”可以是任何C语言的有效表达式,包括数字,变量甚至是函数调用。
print a:将显示整数 a 的值 print ++a:将把 a 中的值加1,并显示出来 print name:将显示字符串 name 的值 print gdb_test(22):将以整数22作为参数调用 gdb_test() 函数 print gdb_test(a):将以变量 a 作为参数调用 gdb_test() 函数 bt:显示当前程序的函数调用堆栈。 display 表达式:在单步运行时将非常有用,使用display命令设置一个表达式后,它将在每次单步进行指令后,紧接着输出被设置的表达式及值。如: display a watch 表达式:设置一个监视点,一旦被监视的“表达式”的值改变,gdb将强行终止正在被调试的程序。如: watch a kill:将强行终止当前正在调试的程序 help 命令:help 命令将显示“命令”的常用帮助信息 call 函数(参数):调用“函数”,并传递“参数”,如:call gdb_test(55) layout:用于分割窗口,可以一边查看代码,一边测试: layout src:显示源代码窗口 layout asm:显示反汇编窗口 layout regs:显示源代码/反汇编和CPU寄存器窗口 layout split:显示源代码和反汇编窗口 Ctrl + L:刷新窗口 quit:简记为 q ,退出gdb 当然,gdb的功能远不止这些,包括多进程/多线程/信号/远程调试等功能在这里均没有提及,有需要的读者可以参考其它信息
gdb调试时设置打印变量完整内容:
set print element 0
查看栈信息
当程序被停住了,首先要确认的就是程序是在哪儿被断住的。这个一般是通过查看调用栈信息来看的。在gdb中,查看调用栈的命令是backtrace,可以简写为bt。
(gdb) bt #0 pop () at stack.c:10 #1 0x080484a6 in main () at main.c:12
也可以通过info stack命令实现类似的功能(我更喜欢这个命令):
(gdb) info stack #0 pop () at stack.c:10 #1 0x080484a6 in main () at main.c:12
查看源程序
当程序断住是,gdb会显示当前断点的位置:
Breakpoint 1, pop () at stack.c:10 10 return stack[top--];
可以用list命令来查看当前断点附近的程序的源代码:
(gdb) list 5 int top = -1; 6 7 8 char pop(void) 9 { 10 return stack[top--]; 11 } 12 13 void push(char c) 14 {
list命令后面还可以更一些参数,来显示更多功能:
- <linenum> 行号。
- <+> [offset] 当前行号的正偏移量。
- <-> [offset] 当前行号的负偏移量。
- <filename:linenum> 文件的中的行行。
- <function> 函数的代码
- <filename:function> 文件中的函数。
- <*address> 程序运行时的语句在内存中的地址。
不过,就算有这些信息,查看代码仍然不大方便。现在新版的gdb都带一个tui的功能,可以通过focus命令开启,其主要界面如下:
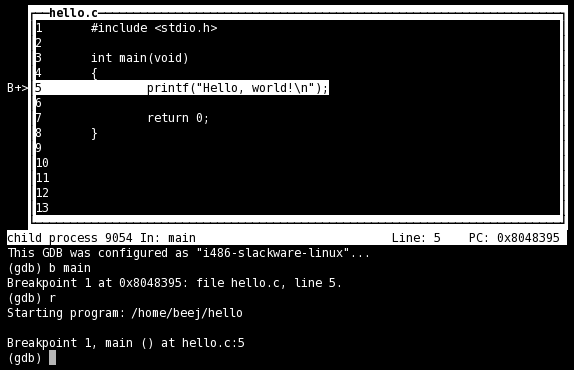
这个界面比起list来说方便多了,能高亮当前语句的执行位置,步进时也会跟着变化,有点使用Turbo C的感觉。
不知道是不是由于focus比较新的缘故,貌似网上并没有多少文章介绍它,虽然它比较容易上手,但也有不少可以介绍的地方,限于篇幅我这里就不做更多的说明,感兴趣的朋友可以看下这篇文章。
查看运行时数据
gdb中查看变量的命令是print,一般用它的简写形式p。它的语法如下:
print [</format>] <expr>
其中参数expr可以是一个变量,也可以是表达式。format表示输出格式,例如,可以用/x来将结果按16进制输出。如下是几个基本的例子:
(gdb) p top $16 = 1 (gdb) p &top $17 = (int *) 0x804a014 <top> (gdb) p 3+2*5 $18 = 13 (gdb) p /x 3+2*5 $19 = 0xd
format的取值范围有如下几种:
- x 按十六进制格式显示变量。
- d 按十进制格式显示变量。
- u 按十六进制格式显示无符号整型。
- o 按八进制格式显示变量。
- t 按二进制格式显示变量。
- a 按十六进制格式显示变量。
- c 按字符格式显示变量。
- f 按浮点数格式显示变量。
查看函数返回值
查看函数返回值是在调试的过程中经常遇到的需求。例如,对于如下函数
int foo() { return 100; }
我们可以以如下方式获取函数的返回值:
(gdb) finish Run till exit from #0 foo () at main.c:9 main () at main.c:15 15 } Value returned is $2 = 100
(gdb) p $eax $3 = 100 (gdb) info registers eax 0x64 100
查看连续内存
可以使用GDB的"@"操作符查看连续内存,"@"的左边是第一个内存的地址的值,"@"的右边则你你想查看内存的长度。
例如,对于如下代码:int arr[] = {2, 4, 6, 8, 10};,可以通过如下命令查看arr前三个单元的数据。
(gdb) p *arr@3 $2 = {2, 4, 6}
查看内存
可以使用examine命令(简写为x)来查看内存地址中的值。x命令的语法如下所示:
x /<n/f/u> <addr>
- n 表示显示内存的长度,也就是说从当前地址向后显示几个地址的内容。
- f 表示显示的格式,如果是字符串,则用s,如果是数字,则可以用i。
- u 表示从当前地址往后请求的字节数,默认是4个bytes。(b单字节,h双字节,w四字节,g八字节)
- <addr> 表示一个内存地址。
例如:以两字节为单位显示前面的那个数组的地址后32字节内存信息如下.
(gdb) x /16uh arr 0xbffff4cc: 2 0 4 0 6 0 8 0 0xbffff4dc: 10 0 34032 2052 0 0 0 0
自动显示
在VisualStudio中,可以通过监视窗口动态查看变量的值。在gdb中,也提供了类似的命令display,它的语法是:
display <expr> display /<fmt> <expr> display /<fmt> <addr>
expr是一个表达式,fmt表示显示的格式,addr表示内存地址。当你用display设定好了一个或多个表达式后,只要你的程序被停下来(单步跟踪时),GDB会自动显示你所设置的这些表达式的值。
几个相关的命令如下:
- undisplay <dnums...> 不显示dispaly
- delete display [dnums] 删除自动显示,不带dnums参数则删除所有自动显示,也支持范围删除,如: delete display 1,3-5
- disable display <dnums...> 使display失效
- enable display <dnums...> 恢复display
- info display 查看display信息
两台Linux机器互传文件
scp local_file remote_username@remote_ip:remote_folder 或者 scp local_file remote_username@remote_ip:remote_file 或者 scp local_file remote_ip:remote_folder 或者 scp local_file remote_ip:remote_file
第1,2个指定了用户名,命令执行后需要再输入密码,第1个仅指定了远程的目录,文件名字不变,第2个指定了文件名;
第3,4个没有指定用户名,命令执行后需要输入用户名和密码,第3个仅指定了远程的目录,文件名字不变,第4个指定了文件名;
scp -r root@192.168.0.161:/work/release/* /xbt/
例子:
scp /home/space/music/1.mp3 root@www.cumt.e.cn:/home/root/others/music
scp /home/space/music/1.mp3 root@www.cumt.edu.cn:/home/root/others/music/001.mp3
scp /home/space/music/1.mp3 www.cumt.edu.cn:/home/root/others/music
scp /home/space/music/1.mp3 www.cumt.edu.cn:/home/root/others/music/001.mp3
* 复制目录:
* 命令格式:
scp -r local_folder remote_username@remote_ip:remote_folder
或者
scp -r local_folder remote_ip:remote_folder
第1个指定了用户名,命令执行后需要再输入密码;
第2个没有指定用户名,命令执行后需要输入用户名和密码;
* 例子:
scp -r /home/space/music/ root@www.cumt.edu.cn:/home/root/others/
scp -r /home/space/music/ www.cumt.edu.cn:/home/root/others/
上面 命令 将 本地 music 目录 复制 到 远程 others 目录下,即复制后有 远程 有 ../others/music/ 目录
======
从 远程 复制到 本地
======
从 远程 复制到 本地,只要将 从 本地 复制到 远程 的命令 的 后2个参数 调换顺序 即可;
例如:
scp root@www.cumt.edu.cn:/home/root/others/music /home/space/music/1.mp3
scp -r www.cumt.edu.cn:/home/root/others/ /home/space/music/
最简单的应用如下 :
scp 本地用户名 @IP 地址 : 文件名 1 远程用户名 @IP 地址 : 文件名 2
[ 本地用户名 @IP 地址 :] 可以不输入 , 可能需要输入远程用户名所对应的密码 .
可能有用的几个参数 :
-v 和大多数 linux 命令中的 -v 意思一样 , 用来显示进度 . 可以用来查看连接 , 认证 , 或是配置错误 .
-C 使能选项 .
-P 选择端口 . 注意 -p 已经被 使用 .
-4 强行使用 IPV4 地址 .
-6 强行使用 IPV6 地址 .
Linux scp命令的使用方法应该可以满足大家对Linux文件和目录的复制使用了。
Linux之scp命令的使用
1. scp简介
1.1 命令功能:
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录。
格式为:scp [可选参数] file_source file_target
1.2 命令参数
- -1 强制scp命令使用协议ssh1
- -2 强制scp命令使用协议ssh2
- -4 强制scp命令只使用IPv4寻址
- -6 强制scp命令只使用IPv6寻址
- -B 使用批处理模式(传输过程中不询问传输口令或短语)
- -C 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
- -p 保留原文件的修改时间,访问时间和访问权限。
- -q 不显示传输进度条。
- -r 递归复制整个目录。
- -v 详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
- -c cipher 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
- -F ssh_config 指定一个替代的ssh配置文件,此参数直接传递给ssh。
- -i identity_file 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
- -l limit 限定用户所能使用的带宽,以Kbit/s为单位。
- -o ssh_option 如果习惯于使用ssh_config(5)中的参数传递方式,
- -P port 注意是大写的P, port是指定数据传输用到的端口号
- -S program 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
2. 命令实践
| 主机名 | IP地址 | 备注 |
|---|---|---|
| web01 | 192.168.200.28 | 测试服务器(一) |
| web02 | 192.168.200.29 | 测试服务器(二) |
2.1 将本机文件复制到远程服务器上
[root@web01 ~]# scp -r /root/test root@192.168.200.29:/tmp/#命令详解:/root 本地文件的绝对路径test 要复制到服务器上的本地文件root 通过root用户登录到远程服务器(也可以使用其他拥有同等权限的用户)192.168.200.29 远程服务器的ip地址(也可以使用域名或机器名)/tmp 将本地文件复制到位于远程服务器上的路径
2.2 将远程服务器上的文件复制到本机
[root@web01 ~]# scp -r root@192.168.200.29:/tmp/test /root/sc/#命令详解:root 通过root用户登录到远程服务器(也可以使用其他拥有同等权限的用户)192.168.200.29 远程服务器的ip地址(也可以使用域名或机器名)/tmp/test 欲复制到本机的位于远程服务器上的文件 /root/sc/ 将远程文件复制到本地的绝对路径
2.3 如果远程服务器防火墙有特殊限制,scp便要走特殊端口,具体用什么端口视情况而定,命令格式如下:
[root@web01 ~]# scp -rP 1234 /root/test root@192.168.200.29:/tmp/
2.4 scp命令延申
#对拷文件夹 (包括文件夹本身)[root@web01 ~]# scp -r /root/sc root@192.168.200.29:/tmp/
#对拷文件夹下所有文件 (不包括文件夹本身)[root@web01 ~]# scp -r /root/sc/* root@192.168.200.29:/tmp/
#对拷文件并重命名[root@web01 ~]# scp -r /root/test root@192.168.200.29:/tmp/test.txt
转载地址:http://ppfci.baihongyu.com/